
0:000:48
Listen
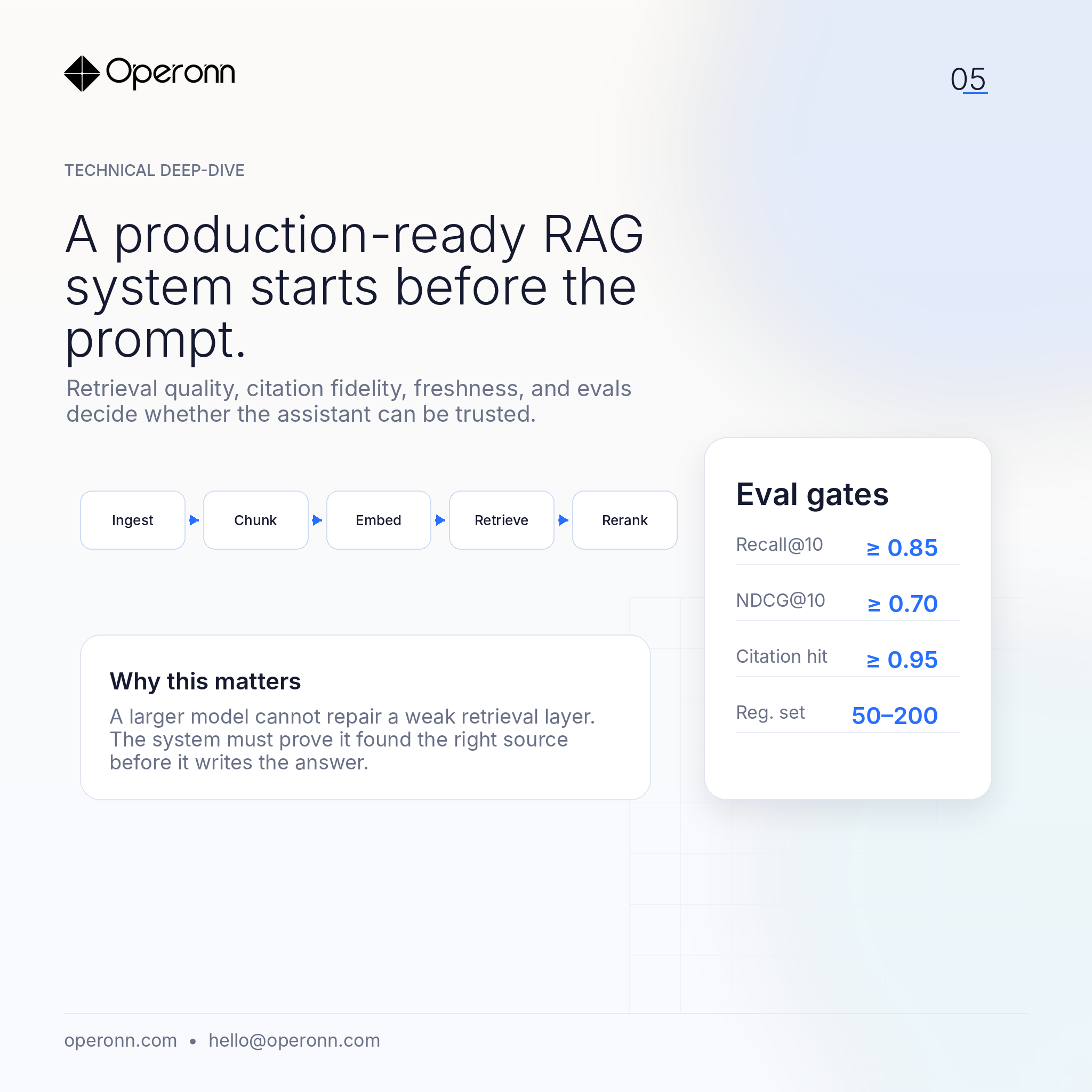
A production-ready RAG system starts before the prompt. The model is only the final step.
The real work is in ingestion, chunking, metadata, hybrid retrieval, reranking, citation fidelity, freshness handling, and evaluation.
Questions a practical retrieval stack should answer
- Did we retrieve the right source?
- Was the source current?
- Can a human inspect the citation?
- Did quality regress after the last index update?
- Does the system refuse when the source set is ambiguous?
At Operonn, our RAG builds are designed around that loop.
A typical baseline
- A frozen regression set
- Recall@K / NDCG@K checks
- Citation hit-rate review
- Domain-specific hallucination tests
A bigger model cannot reliably compensate for weak retrieval.
Good retrieval is the product. The LLM is the interface.